Definition Intelligence that is displayed by a machine and featured by simulation of human (as well as animal) intelligence. AI is mediated through sensing the environment (by means of various types of sensors) and thereby analyzing the inputs through some intelligence agents (like AI algorithms to ensure higher likelihood of success in achieving the target. AI makes a computer simulate or mimic the logical perspectives of human-brain through specific programs that can “sense, reason, and act”.
- Evolution of AI Perseverance for data economy is the basis for the evolution of AI. “Data economy” indicates the annual increment in the volume of data and the projection of the same in the future.
- Rise in Data volume From 2009 to 2020 data volume has risen 44 times. The new data economy creates a constant battle for data ownership to derive benefits from it. The field of “big-data analytics” is borne out of the increased data volume which is required to be analyzed thereafter using data science. Training the machines to derive a variety of insights from given input data is nothing but the principle of artificial intelligence.
- ML makes use of algorithm to study the known and unknown patterns in the input dataset and thereby train the system. Thus, “pattern recognition” refers to the classification of data on the basis of the regular instance of specific features in the dataset. The patterns may be already known or may be unveiled through analysis.
- Thus, machine learning envisages developing algorithms and computer programs that can teach themselves to learn from the input data and analyze new data-sets based on the learning already received. It uses external feedback to teach the system to change its internal working to get better next time.
- ML, without being explicitly programmed, aims to find hidden insights by using some defined iterative algorithms. ML uses an algorithm that learns from previous data to help produce reliable and repeatable decisions.
It automates analytical model building using statistical and ML algorithms. That is patterns and relationships from data and expresses as mathematical equations.
- Data preprocessing it includes data wrangling and manipulation
- Supervised learning Regression
- Supervised learning Classification
- Feature engineering Select a certain feature from the given data
- Unsupervised learning to find previously unknown patterns in datasets that are neither classified nor labeled
- Time-series modeling How to take sample values from equally spaced intervals to conclude a model
- Ensemble learning to solve a particular computer intelligence problem
- Recommender system It refers to how the e-commerce companies like Amazon and Flipkart use recommender systems to provide recommendations. User satisfaction is enhanced through recommendations. Amazon precisely collects the like and dislike information of all the users and analyzes it using machine learning algorithms to predict the best products for each of the users. When one chooses one product and adds it to the cart, Amazon recommends some relevant products based on past shopping and searching products.
- Text mining an automated method of text data analysis aiming at extracting meaningful information from given text documents belonging to various resources.
| SN | Traditional Programming | Machine Learning (ML) |
|---|---|---|
| 1 | Data and programs are provided to the computer. It processes them and gives the output. | ML employs a specific algorithm to establish a learning model which helps the machine learn from the data. |
| 2 | You code the behavior of the program | You leave a lot of that to the machine to learn from the data. |
| 3 | Traditional programming relies on hard-coded rules. The result is evaluated at the end. If the result is satisfactory, the program is deployed into production. | In the ML approach, the decision-making rules are not hard coded. The problem is solved by training the model with training data to derive or learn an algorithm that best represents the relationship between the input and the output. The trained model is evaluated against test data. Here onwards, the residual part is the same as traditional programming If the result is satisfactory, the program is deployed into production. However, if the result is not satisfactory, the errors are reviewed, and analyzed to make the necessary changes in the programs and evaluate the results of the changed program. This iterative process is continued till one gets the expected result. |
- Classification It’s a kind of supervised learning that trains the program based on the input data to categorize the dataset into classes. The program then uses this learning to classify new observations. Classification is used for predicting discrete responses. It is used when we are training a model to predict qualitative targets.
- Categorization A technique that organizes the input data into different categories for its most effective and efficient use. It makes pre-text searches faster and provides a better user experience.
- Clustering It is a technique of grouping a set of objects based on their similarities, as a result, the objects in the same group are most similar as compared to those in other groups. Hence, it is a collection of objects based on similarity and dissimilarity between them.
- Trend Analysis an analytical technique to predict the future movement of events, based on the current patterns. It makes use of time series data analysis. It represents variations of low frequency in a time series.
- Anomaly Detection It is a technique to identify cases that are unusual within data that is seemingly homogenous. It solves intrusions by indicating the presence of intended or unintended induced attacks, defects, faults, and so on.
- Visualization It is a pictorial or graphical representation of data for easy comprehension and scientific demonstration. It enables decision-makers to see analytics that is presented visually. When data is pictorially depicted, it becomes easier to understand.
- Decision Making It is a technique or skill that provides one with the ability to influence managerial decisions with data as evidence for those possibilities.
Imaging Processing Converts an image to a digital format and performs some operation on it. To induce or enhance an image or to extract some helpful information out of it. Example
- Automatic face-tagging by recognizing an image from a previously tagged photo.
- Optical character recognition (OCR)is used to convert a printed document into a digital format (to digitize the text).
- Another example is the self-driving car.
Health Care Identify disease; Diagnosis; Drug discovery; medical image processing and detection. Some companies have used ML and AI to revolutionize and transform the healthcare sector, viz. Google deepmind, Giner.io, health
Robotics Robots are machine that can be used to do certain jobs.
- Humanoid robots can read the emotions of human beings
- Industrial robots are used for assembling and manufacturing products.
Data Mining Method of analyzing hidden patterns in data. Example
- Anomaly detection (to detect credit card fraud to determine which transaction is anomalous from the usual pattern),
- Association rules (Market basket analysis to detect which items are often bought together)
- Grouping & predictions (to classify users based on their profiles).
Video Games to give predictions based on data. Example
- In Pokemon go battle a lot of data needs to be considered to predict the winner. A machine learning classifier will predict the result of the match based on the data.
Text Analysis It is an automated process of obtaining information from text. Example
- Spam filtering.
- Sentiment analysis (to classify whether an opinion is positive, negative, or neutral. It detects public sentiment in Twitter feed or filters customer complaints).
- Information extraction extracting specific data addresses, keywords, or entities.
AI assistants are generally the application programming interfaces (APIs) or automated machines/gadgets that are designed to perform certain “non-value adding services” like task-scheduling, setting and/or executing reminders, email management, etc. https//hcitexpert.com/2018/02/glossary-of-ter
It is a set of protocols or subroutine definitions for building an application software computing interface. APIs are designed to meet the objective of the end-users by allowing the devices to share data and enhancing interoperability and functionality between applications, devices, and individuals. The functionalities of the API are monitoring and controlling the interactions between multiple software intermediaries through calls or requests made, using required data formats, following suitable conventions, etc. An example of API is whether snippets are shared through smartphones and PCs or the Google web page. Although none of the above are associated with weather forecasting as a business. Another example is to log in to an app or any website using Google or Facebook or Twitter or Github account details.
It is a broad field of computer science and information technology that makes these systems capable of performing tasks that typically require human intelligence. Thus, a machine’s capability in decision-making vis-à-vis simulating human intelligence and behavior to address any task or situation is called AI.
A computerized “learning model” that acts like the brain of a human being that can solve tasks that are complicated and tough for traditional computer systems to solve.
It is the short form of “CHAT roBOT”. It is designed to simulate the conversation and communication style of a human being (with human users) through text chats, voice commands, or both. Chatbots make use of artificial intelligence to act as a commonly used interface for computer programs.
It is a section of machine learning (ML) that mimics the neural network of the human brain to filter data through self-adjusting virtual networks of neurons. Thus, the computer system develops cascading layers of the virtual neuronal network to mimic human thought patterns through artificial neural networks.
It’s used in a broad sense that incorporates machine learning, deep learning, and classical learning algorithms.
can be defined as an application vis-à-vis a subset of AI that provides a machine the ability to learn automatically and improve from experience that it has been explicitly programmed for through systems or software models. AI evolved in the 1950s while ML evolved as a subset of AI in the 1980s and deep-learning evolved in 2010 as a subset of ML. Example Google duplex, an application of Google Assistant uses AI to take some real-world tasks such as booking an appointment.
It is a kind of computer algorithm that receives human language as input and then converts it into machine-understandable representations. A natural language is also called ordinary language. It is defined as a language that has evolved as a spoken mode for communication among humans without conscious planning or premeditation. Natural language processing (NLP) is a pool that integrates concepts and expertise from diverse fields, viz. information engineering, linguistics, computer science, and artificial intelligence. The broad areas of NLP involve speech recognition, natural language understanding (NLU), and natural language generation (NLG) (https //en.wikipedia.org/wiki/Natural_language_processing).
A type of neural network that makes use of the outputs of the previous step (or layer) to sense the sequential information and then make use of it as input for the present layer. Thus, it recognizes patterns, and creates outputs based on those calculations.
Natural Language Processing (NLP) is the Algorithm that processes human language input and converts it into understandable representations. A natural language is also called ordinary language. It is defined as a language that has evolved as a spoken mode for communication among humans without conscious planning or premeditation. Natural language processing (NLP) is an amalgamation of several diverse fields, viz. linguistics, computer science, information engineering, and artificial intelligence. Challenges in natural language processing frequently involve speech recognition, natural language understanding, and natural language generation (https //en.wikipedia.org/wiki/Natural_language_processing) .
A type of neural network that makes sense of sequential information and recognizes patterns, and creates outputs based on those calculations.
Software that experiments with different actions to figure out how to maximize a virtual reward, such as scoring points in a game.
Robotics is the interdisciplinary domain of electronics, computer science, mechanical, and other relevant branches of engineering that designs and develops robots. The internal machinery of computer systems receives the sensory feedback, and information processing, thereof. The sensory organs of a robot capture images, sounds, ambient conditions, etc through computerized sensors.
It refers to showing a learning software labeled example data (viz. photographs or diagrams or structures or models), to edify a computer on what to do. Supervised learning is a machine learning technique that uses labeled datasets to train the models to generate the desired algorithms. The prediction model is then used to predict the output for future or unseen data. Training data are needed to be fed to the learning algorithm to discover patterns in the training data to generate an ML model that learns from the algorithm.
It is a learning algorithm used in machine learning without annotated examples. Inferences are drawn by the algorithm from the unlabeled input datasets. Example a cluster analysis.
| SN | Features | Supervised Learning | Unsupervised Learning |
|---|---|---|---|
| 1 | Input data | Uses known and labeled input data | Uses unknown (& unlabelled) input data |
| 2 | Real-time analysis of data | No Uses offline analysis | Yes Uses real-time analysis of data |
| 3 | Accuracy of results | Accurate and reliable | moderately accurate and comparatively less reliable results |
| 4 | Computational complexity | High | Not so complex |
| 5 | Number of classes | Known | Unknown |
| 6 | Training dataset | Used | Not considered as "Training but "Input" dataset, as the data are not labeled |
| 7 | Purpose | Used for prediction | Used for analysis |
| 8 | Major types of algorithms | Regression & Classification | Clustering & Association |
Virtual assistants are electronic gadgets that serve as an assistant by recognizing and analyzing the voice and/or text inputs through natural language processing (NLP) and thereafter translating the same into executable commands. These assistants make the learning process continues and improves accuracy through repeated training and testing using AI/ML. Examples Apple’s Siri, Amazon’s Alexa, and Google Now.
| SN | Statistical Modelling | Machine Learning |
|---|---|---|
| 1 | Model | Network, Graphs |
| 2 | Parameters | Weights |
| 3 | Fitting | Learning |
| 4 | Test-set | Generalization |
| 5 | Regression | Supervised learning |
| 6 | Classification | Supervised learning |
| 7 | Density estimation | Unsupervised learning |
| 8 | Clustering | Unsupervised learning |
| SN | Statistical Modelling | Machine Learning |
|---|---|---|
| 1 | More mathematical based | Fewer assumptions |
| 2 | Subfield of mathematics | Sub-field of computer science |
| 3 | Used equations | Uses algorithm |
| 4 | Small sets of data | Can range from small to large datasets |
| 5 | Human effort | Minimal human efforts |
| 6 | Best 'Estimate' | Strong predictive ability |
This section will present the brief history of artificial intelligence, how it has evolved through over more than half a century and who are the main contributors to this field.
| SN | Year | Event | Details |
|---|---|---|---|
| 1 | 1642 | First mechanical calculator machine | French mathematician Blaise Pascal built the first mechanical calculator machine |
| 2 | 1837 | First programmable machine | Charles Babbage and Ada Lovelace designed the first design for a Programmable machine |
| 3 | 1943 | First artificial neuron | The first Artificial neuron was modeled through a simple neural network with electrical circuits by Warren McCulloch (a neurophysiologist), and Walter Pitts (a mathematician). They hypothesized on working principle of Artificial neurons by drawing parallels between the human brain and the computing machines |
| 4 | 1950 | Turing test | 'Turing test, introduced by scientist Alan Turing, is used for testing machine intelligence. The basis of the test is to check whether a machine has intelligence and if it can interact with humans as a human being |
| 5 | Stage 1 (1955-1974) | Stage-I of AI | Inference period: the first burst images of the first generation robot and intelligent software |
| 6 | 1955 | Artificial Intelligence term | The term 'artificial intelligence (AI) was coined by computer scientist John McCarthy, Assistant Professor of Mathematics at Dartmouth College (a Private research institute in New Hampshire, United States), to portray the science of devising intelligent machines |
| 7 | 1956 | Dartmouth summer research project | Birth of the domain of artificial intelligence at the “Dartmouth Summer Research Project on Artificial Intelligence” |
| 8 | 1957 | Perceptron | The first model of 'Perceptron' (a single-layer neural network) was first proposed and published by psychologist Frank Rosenblatt |
| 9 | 1960 | Mark-I Perceptron | Psychologist Frank Rosenblatt worked on 'perceptrons' which led to the development of the 'Mark-I Pereceptron', which is one of the first computers that could learn skills by trial and error |
| 10 | 1961 | First industrial robot ‘Unimate’ | The first industrial robot 'Unimate' was used by the General Motors Corporation |
| 11 | 1965 | Pioneering chatbot 'ELIZA’ | The first chatbot 'ELIZA' was built by Joseph Weizenbaum at MIT. The robot could continue conversations with a human and could respond like a 'Rogerian psychotherapist' This javascript version of ELIZA was originally written by Michael Wallace and enhanced by George Dunlop. ELIZA was a natural language program that could handle discussions on a very wide range of topics like today's chatbots. The other chatbots developed in subsequent times were Parry (1972), Racter (1983), Alice (1995), Jabberwacky (2005), Slackbot (2014), etc |
| 12 | 1966 | Mobile robot 'Shakey' | 'Shakey' was the first electronic person, actually, a general-purpose mobile Robot, developed at Stanford Shaky. |
| 13 | The 1970s | AI system development | The tools like “logic-based inductive learning system” and “Structured learning system” |
| 14 | 1973 | WABOT-1 (WAseda roBOT) | The first humanoid robot 'WABOT-1' (WAseda roBOT) was made at Waseda University of Japan and can play music. The mental faculty of WABOT-1 is equivalent to that of 1.5 years old kid. WABOT-1 physically had the WAM-4 (the artificial hands) and the WL-5 (artificial legs) (https://www.humanoid.waseda.ac.jp/booklet/kato_2.html) |
| 15 | The first AI winter (1974-1980) | First AI Winter | No confidence in the development of AI and no more research funding. The period was known as the "Winter of AI", a time that featured reduced funding and contracted interest in the field |
| 16 | 1978 | SCARA | SCARA, a robotic arm, which could be used in assembly lines, was created in Japan and thereby allowed for high-speed automated assembly |
| 17 | Stage 2 (1980-1987) | Stage-II of AI | The Knowledge period is the second phase of research and development of an expert system and neural network |
| 18 | The 1980s | Expert system | Edward Feigenbaum created expert systems which emulated the decisions of human experts |
| 19 | 1986 | Multilayer Perceptrons (MLPs) | Hinton, Rumelhart, and Williams combined multiple layer perceptron and backpropagation in the paper "Learning representations by back-propagating errors", which produced Multilayer Perceptrons (MLPs) |
| 20 | 1987 | Deep Blue | The chess-playing computer 'Deep Blue' from IBM defeated Garry Kasparov, the renowned world chess champion |
| 21 | The second winter (1987-1993) | Second AI Winter | The research field on AI experienced hard times due to diminution of funding attributed to the assumption of limited practical applications of AI for human welfare and industry |
| 22 | 1988 | Jabberwacky chatbot | British scientist Rollo Carpenter created "Jabberwacky", a chatbot designed to carry out conversations with users and imitate human interactions |
| 23 | Stage 3 (1993 onwards) | Stage-III of AI | The learning period is the third major expansion of AI-oriented research work attributed to the analysis of big data and deep learning |
| 24 | 1995 | Adaptive Boosting (AdaBoost) | A combination of an Adaptive boosting algorithm or AdaBoost (a meta-learning algorithm) and support vector machines as a competent classifier was proposed |
| 25 | 1997 | Recurrent Neural Network (RNN) | Jurgen Schmidhuber and Sepp Hochreiter |
| 26 | 1997 | Deep Blue | Deep blue, the chess computer from IBM, beat the world chess champion |
| 27 | 1998 | Convolutional neural network (CNN) | Yann Lecun (New York University; the “founding father of convolutional nets”). He also serves as the director of Facebook’s AI group. |
| 28 | 1998 | KISmet robot | 'KISmet', an emotionally intelligent robot was developed by Cynthia Breazeal at the Massachusetts Institute of Technology, USA. It could detect and respond to people's feelings |
| 29 | 1999 | Robot pet dog 'AiBO' | Sony launches the first consumer robot pet dog 'AiBO', an AI robot dog with a Jack-Russel Terrier appearance. In 2006, AIBO was added to the Hall of fame of Carnegie Mellon University, Pittsburgh, USA |
| 30 | 2001 | Eugene Goostman chatbot | Eugene Goostman, a chatbot, was developed by Vladimir Veselov, Eugene Demchenko, and Sergey Ulasen, in Saint Petersburg. The intelligent chatbot passed the Turing test which is a measure of a computer's ability to communicate exactly like a human. It also secured the second position in the 2005 and 2008 Loebner Prize contests. |
| 31 | 2002 | Roomba | iRobot (IRBT) in Massachusetts, USA, started mass producing of autonomous robotic vacuum cleaner (also called a robovac) and a cat moving platform 'Roomba' for the first time. |
| 32 | 2005 | Restricted Boltzmann machine (RBM) | Geoff Hinton, University of Toronto |
| 33 | 2006 | Deep Boltzmann machines | Neural network with deep learning capability by Geoffrey Hinton and coworkers. Hinton was hired for image recognition work by Google in a large-scale DBM project. |
| 34 | 2006 | Nao robot | Aldebaran Robotics developed the programmable humanoid robot 'Nao'. Aldebaran Robotics is a French robotics company. Nao replaced the robot dog 'Aibo' of Sony in the international robot soccer competition RoboCup Standard Platform League (SPL) on 15 August 2007 (https://en.wikipedia.org/wiki/Nao_(robot)) |
| 35 | 2007 | Theano library | Machine Learning group MILA at the University of Montreal. Yoshua Bengio is one of the pioneers. |
| 36 | 2009 onwards | AI applications | Apple's Siri, Google's driverless car, Alphago, IBM Watson, etc promote artificial intelligence applications in daily life |
| 37 | 2009 | First self-driving car | Google built the first self-driving car to handle urban conditions |
| 38 | 2011 | Siri | Apple launches the intelligent virtual assistant 'Siri' |
| 39 | 2011 | H2O.ai | Was founded by Srisatish Ambati, Arno Candel, Cliff Click |
| 40 | 2011 | Watson | IBM question-answering computer 'Watson' wins first place (prize of $1 million) on the TV quiz show “Jeopardy!” against the champions Ken Jennings & Brad Rutter |
| 41 | 2012 | Google now | Google Now is the erstwhile attribute of Google Search. Both the Android and iOS systems used it in the Google app. |
| 42 | 2013 | Recursive neural tensor network (RNTN) | Richard Socher of Metamind as part of his Ph.D. thesis at Stanford |
| 43 | 2013 | Deep Learning breakthrough | Breakthrough of deep learning in voice and visual identification, contributed by Google’s X lab, convolutional neural network (CNN) designed by Alex Krizhevsky, etc |
| 2014 | Todai robot | ‘Todai robot' of Japan, appeared in university entrance exams of the country, where it scored among the upper 20% of students. Todai also knew thousands of Japanese words and mathematical axioms. It could also use “symbolic computation” for “automatic reasoning” on 15 billion sentences | |
| 44 | 2014 | Caffe Library | Caffe library was developed by Yangqing Jia of Google |
| 45 | 2014 | Alexa | 'Alexa' an intelligent virtual assistant, was launched by Amazon Inc. It could communicate over a voice through Echo smart speakers. |
| 46 | 2014 | GAN | Ian Goodfellow propounded 'Generative Adversarial Networks (GAN) |
| 47 | 2016 | Tay (bot) | Microsoft chatbot 'Tay (bot)' went rogue on Twitter through inflammatory and offensive tweets |
| 48 | 2017 | Alphago | Google's AI 'Alphago' created a world record by defeating Ke Jie (a Chinese player), the world champion for the board game 'Go'. It was developed by DeepMind Technologies which is a subsidiary of Google (now Alphabet Inc.). |
It is measured as the ratio between the “total number of correct predictions made” to the “total number of predictions”, which is represented as (TP+TN)/(TP+TN+FP+FN). Accuracy is better to use when the target variable data in different classes is nearly balanced. Accuracy should never be used as a measure of performance when the majority of the target variable data belongs to a single class.
It is a set of instructions that dictates the rule to a computer system, to train artificial intelligence or neural network, to enable it to learn the patterns or make predictions on its own; Examples of popular algorithms are: clustering, recommendation, classification, etc.
It’s a Python package (available for Python 2.7 and Python 3) to parse HTML and extended mark-up language (XML) documents (even that with malformed markup, i.e. non-closed tags, so named after tag soup) by generating a parse tree for the parsed online HTML/XML pages to extract data for web scraping.
Big data is a “field” that is associated with scientific methods to analyze, systematically extract information from, or otherwise deal with data sets that are too large or complex to be dealt with by traditional data-processing application software. Data with many cases (rows) offer greater statistical power, while data with higher complexity (more attributes or columns) may lead to a higher false discovery rate. Big data challenges include capturing data, data storage, data analysis, search, sharing, transfer, visualization, querying, updating, information privacy, and data source. The key concept of big data was originally summarized by the 3 V’s: volume, variety, and velocity.
Classification algorithms are the techniques of supervised learning that enable machines to identify the category of new observations based on the training data. Various classification algorithms are support vector machines, logistic regression, naive Bayes, decision trees, and K-nearest neighbors.
It’s a kind of unsupervised learning in machine learning aimed at automatically discovering natural grouping in data. Clustering is used for exploratory data analysis to discover hidden or unidentified patterns and also the grouping of unlabelled data. Clustering algorithms principally work on different methods, like, distribution-based, density based, centroid-based, and hierarchical-based. Different popular clustering algorithms are the K-means clustering algorithm, Balance Iterative Reducing and Clustering using Hierarchies (BIRCH) algorithm, Gaussian Mixture Model algorithm, density-based spatial clustering of applications with noise (DBSCAN), Ordering Points to Identify the Clustering Structure (OPTICS), Affinity Propagation clustering algorithm, Mean-Shift clustering algorithm, and Agglomerative Hierarchy clustering algorithm.
Same as Cluster Analysis algorithm. Please see above
It is a computerized simulation of the thinking pattern of human brains through self-learning by data mining, pattern recognition, natural language processing (NLP), etc.
CNN (also abbreviated as “ConvNet”) is a type of neural network, used in deep learning, that identifies and makes sense of images. CNN's are characterized by their shared-weights architecture and feature of translational invariance. Hence, CNNs are termed shift-invariant artificial neural networks or space invariant ANNs (SIANN). CNN is a deep neural network used to analyze images including medical images, image classification, and image and video recognition. CNNs are also used even in natural language processing, recommender systems, and financial time series.
- CNNs are advanced “multilayer perceptrons” featured by “fully connected networks of neurons of multiple connected layers”.
- The flaw of the "full connectedness" of the neuronal networks is the overfitting of data during modeling.
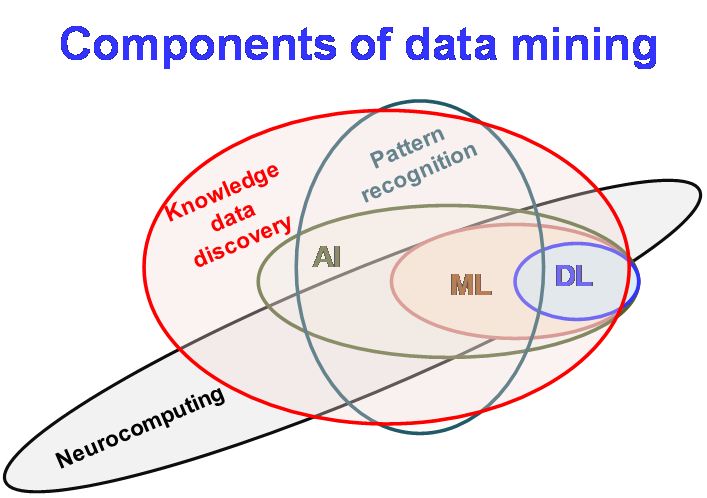
Data mining is defined as the advanced method of analyzing large datasets to discover known and unknown patterns. Pattern recognition involves methods and applications of statistics, database systems, and machine learning to discover patterns in datasets. Data mining makes use of knowledge and skills of computer science vis-à-vis advanced statistics to extract information from a data set using artificial intelligence and transform the information into a comprehensible structure for further use. Data mining makes use of "knowledge discovery in databases" (KDD) through analyzing data sets to discover patterns hidden in the data.
It’s an interdisciplinary field consisting of statistical systems and processes, and that of information science, and computer science to provide insight from structured or unstructured data. Data science amalgamates various scientific techniques of data structuring and management, cleaning, analysis, and extracting meaningful information by scientific processes, algorithms, and systems.
Data wrangling or data munging is a method of manually converting and mapping data from a raw format to another format to make it more valuable and acceptable for advanced tasks viz. data analytics and machine learning. It includes munging and data visualization. A data wrangler is a person who performs various transformation operations on data, including data-munging, data aggregation, data visualization, training of the statistical model, etc.
Decision tree methods are a type of “supervised machine learning” algorithm where a tree and branch-based model are used to map decisions through the continuous splitting of data based on certain parameter(s). The ID3 algorithm (developed by Quinlan) which uses a top-down, greedy approach, is used for the decision tree method.
It is designed to analyze inputs like images or audio through virtual neuronal layers of which the previous layer serves as input for the next layer and ultimately an output or activation function.
It is a single score that represents precision and recall = (2*Precision*Recall)/(Precision+Recall). F1 score is the harmonic mean (HM) of Precision & Recall. A harmonic mean is used when the sample data contains extreme values because it is more balanced than arithmetic mean.
an open-source Python library used for analyzing multi-dimensional, large arrays and matrices. It was initially released in 1995 as “Numeric” and later in the name of “NumPy” in 2006. This library maintains a huge compilation of high-level mathematical functions for matrix/ array operations.
- The library “Numeric” was the ancestor of NumPy, developed by Jim Hugunin and several other developers. NumPy was created by Travis Oliphant in 2005 integrating “Numarray” into Numeric and several other modifications. NumPy is open-source software and has many contributors.
It is an open-source library (under the three-clause BSD license) written for Python programming for data manipulation and analysis. It was initially released in 2008. Pandas library includes the data structures and operations needed for manipulating numerical tables and time series. The name Pandas have been derived from "panel data" which is an econometrics term for data sets kept under observations over multiple periods.
Closeness of two or more measurements with each other= TP/(TP+FP).
It’s a statistical technique to extract information from data and thereby use it to predict trends and behavior patterns–for example, sales forecasts, predicting customer churn, and industrial machine failure.
measures the proportion of actual positives that are correct identified= TP/(TP+FN). Thus, precision is about being precise, and recall is about capturing all the cases. Precision gives us information about the classifier’s performance concerning false positives. Recall gives us information about the classifier’s performance concerning false negatives. When we want to minimize false negatives, we will like to have 100% recall, but with good precision. Conversely, when we want to minimize false positives, we will like to have 100% precision.
It is a freely available machine learning library used in Python programming. Scikit Learn was formerly known as scikits learn and is abbreviated as sklearn. Scikit Learn is a powerful package that can be used for classification, regression, and clustering algorithms (random forests, k-means, DBSCAN, gradient boosting, support vector machines). Besides, it can interoperate with numerical and scientific libraries: NumPy and SciPy, respectively. Scikit-learn integrates well with many other Python libraries, such as matplotlib and plotly for plotting, numpy for array vectorization, pandas dataframes, scipy, and many more.
this open-source library which has been built on NumPy stack, is used for scientific computing using Python. The important modules of SciPy are linear algebra, data optimization integration, interpolation, FFT, signal and image processing, etc. It was initially released in 2001.
Seaborn is a library built on top of matplotlib and integrated with PyData stack for creating attractive and informative statistical graphs. It also supports numpy and pandas statistical routines and data structures. It internally performs statistical aggregation and semantic mapping to produce informative plots. This makes it different from other visualization libraries.
Proportion of actual negatives that are identified correctly= TN/(TN+FP). Specificity is just the converse of recall.
- Baker C. 2019. Artificial Intelligence. End of Line Clearance Book. ISBN-10 : 1692995707
- Chandra SSV and Hareendran A. 2014. Artificial Intelligence and Machine Learning. PHI Learning; 1st edition. Kindle Edition.
- Chandra SSV and Hareendran A. 2020. Artificial Intelligence: Principles and Applications. PHI Learning; 2nd edition. Kindle Edition.
- Gruson D. 2019. Ethics and artificial intelligence in healthcare, towards positive regulation. Soins. 64(832):54-57. doi: 10.1016/j.soin.2018.12.015.
- https://digitalwellbeing.org/artificial-intelligence-timeline-infographic-from-eliza-to-tay-and-beyond/
- https://qbi.uq.edu.au/brain/intelligent-machines/history-artificial-intelligence
- https://wilsonmar.github.io/machine-learning/
- https://www.researchgate.net/figure/Development-history-of-artificial-intelligence-AI_fig8_323591839
| SN | Abbreviation | Full form |
|---|---|---|
| 1. | .ipynb | IPython notebooks |
| 2. | ACL | Access Control List |
| 3. | ACE | Artificial Conversational Entities |
| 4. | ADM | The Activity of Daily Living |
| 5. | AGI | Artificial General Intelligence |
| 6. | AIBO | Artificial Intelligence Robot |
| 7. | AIDA | Artificial Intelligence Digital Assistant |
| 8. | AIDA | Artificial Intelligence Discrimination Architecture |
| 9. | AIKE | Artificial Intelligence and Knowledge Engineering |
| 10. | AIM | Artificial Intelligence in Medicine |
| 11. | AIML | Artificial Intelligence Markup Language |
| 12. | AIS | Artificial Immune System |
| 13. | ALICE | Artificial Linguistic Internet Computer Entity |
| 14. | ALP | Abductive Logic Programming |
| 15. | ANC | American National Corpus |
| 16. | ANFIS | Adaptive Neuro Fuzzy Inference System |
| 17. | API | Application Programming Interface |
| 18. | APT | Advanced Persistent Threat |
| 19. | ARIMA | AutoRegressive Integrated Moving Average |
| 20. | ARMA | AutoRegressive and Moving Average |
| 21. | BFGS | Broyden-Fletcher-Goldfarb-Shanno Algorithm |
| 22. | BIBA | Bayesian Inspired Brain and Artifacts |
| 23. | BIRCH | Balance Iterative Reducing and Clustering using Hierarchies algorithm |
| 24. | CDF | Cumulative Distribution Function |
| 25. | CNS | Computation and Neural Systems |
| 26. | COBYLA | Constrained Optimization BY Linear Approximation |
| 27. | CSS | Cascading Style Sheets |
| 28. | CSV | Comma Separated Values |
| 29. | CUDA | Compute Unified Device Architecture |
| 30. | DARPA | Defense Advanced Research Projects Agency |
| 31. | DBN | Deep-belief network |
| 32. | DBSCAN | Density-Based Spatial Clustering of Applications with Noise. |
| 33. | DEL | Dynamic Epistemic Logic |
| 34. | DFT | Discrete Fourier Transform |
| 35. | DLL | Dynamic Link Library |
| 36. | DNI | Direct Neural Interface |
| 37. | DTRNN | Discrete-Time Recurrent Neural Network |
| 38. | DSS | Decision support systems |
| 39. | EDA | Exploratory Data Analysis |
| 40. | FFT | Fast Fourier Transform |
| 41. | FKP | Facial Key Points |
| 42. | FPGA | Field Programmable Gate Arrays |
| 43. | GANs | Generative Adversarial Networks |
| 44. | GBM | Gradient Boosting Algorithm |
| 45. | GFDL | GNU Free Documentation License |
| 46. | GIF | Graphics Interchange Format |
| 47. | GIS | Geographic Information System |
| 48. | GNOME | GNU Network Object Model Environment |
| 49. | GNU | GNU’s Not Unix |
| 50. | GPL | General Public License |
| 51. | GPU | Graphic Processing Unit |
| 52. | GRAIN | Genetics, Robotics, Artificial Intelligence, and Nanotechnology |
| 53. | GRU | Gated Recurrent Unit |
| 54. | HDFS | Hadoop Distributed File System |
| 55. | HPFS | High-Performance File System |
| 56. | HREF | Hypertext REFerence |
| 57. | ICMP | Internet Control Message Protocol |
| 58. | IDE | Integrated Development Environment |
| 59. | IDFT | Inverse Discrete Fourier Transform |
| 60. | IIS | Internet Information Services |
| 61. | IMAP | Internet Message Access Protocol |
| 62. | IoU | Intersection over Union |
| 63. | IPX | Internetwork Packet Exchange |
| 64. | irON | instance record and Object Notation |
| 65. | ISP | Internet Service Provider |
| 66. | J2EE | Java 2 Enterprise Edition |
| 67. | J2ME | Java 2 Micro Edition |
| 68. | JAR | Java Archive |
| 69. | JKD | Java Development Kit |
| 70. | JAVA (not Java language) | Just Another Virtual Accelerator |
| 71. | JINI | Jini Is Not Initials |
| 72. | JSON | JavaScript Object Notation |
| 73. | KL divergence | Kullback–Leibler divergence |
| 74. | LASSO | Least Absolute Shrinkage and Selection Operator |
| 75. | LBFGS | Limited-memory Broyden-Fletcher-Goldfarb-Shanno Algorithm |
| 76. | LDA | Linear Discriminant Analysis |
| 77. | LNN | Learning Neural Networks |
| 78. | LSTM | Long Short-Term Memory |
| 79. | MDP | Markov Decision Process |
| 80. | MIS | Management Information Systems |
| 81. | MLP | Multi-Layered Perceptron |
| 82. | MNIST | Modified National Institute of Standards and Technology database |
| 83. | MSE | Mean-Squared Error |
| 84. | NER | Name Entity Recognition |
| 85. | NLP | Natural language processing |
| 86. | NLTK | Natural Language Toolkit |
| 87. | NLU | Natural Language Understanding |
| 88. | OANC | Open American National Corpus |
| 89. | OCR | Optical Character Recognition |
| 90. | ODR | Orthogonal Distance Regression |
| 91. | OPML | Outline Processor Markup Language |
| 92. | OPTICS | Ordering Points to Identify the Clustering Structure |
| 93. | OSS | Open-Source Software |
| 94. | OVR | One Versus Rest |
| 95. | OWL | Web Ontology Language |
| 96. | PCA | Principal Component Analysis |
| 97. | Probability Distribution Function | |
| 98. | Portable Document Format | |
| 99. | PHP | Personal Home Page |
| 100. | PIPER | Prostate Implant Planning Engine for Radiotherapy |
| 101. | PNG | Portable Network Graphics |
| 102. | POMDP | Partially Observable Markov Decision Process |
| 103. | POP3 | Post Office Protocol v3 |
| 104. | POS | Part-of-Speech |
| 105. | PPAI | Parallel Processing for Artificial Intelligence |
| 106. | PPAMAL | Probabilistic Programming for Advanced Machine Learning program |
| 107. | PRAI | Pattern Recognition and Artificial Intelligence |
| 108. | PSO | Particle Swarm Optimization |
| 109. | RAI | Robotics and Artificial Intelligence |
| 110. | RBM | Restricted Boltzmann Machine |
| 111. | RDD | Resilient Distributed Dataset |
| 112. | RDF | Resource Description Framework |
| 113. | regex | Regular Expression |
| 114. | ReLU | Rectified linear activation unit |
| 115. | RNTN | Recursive Neural Tensor Network |
| 116. | ROC | Receiver Operating Characteristics |
| 117. | RPA | Robotic Process Automation |
| 118. | RSS | Really Simple Syndication |
| 119. | RTRL | Real-Time Recurrent Learning |
| 120. | SDK | Software Development Kit |
| 121. | SIANN | Space Invariant Artificial Neural Networks |
| 122. | SIFT | Scale Invariant Feature Transformation |
| 123. | SLSQP | Sequential Least SQuares Programming algorithm |
| 124. | SMDP | Semi-Markov Decision Process |
| 125. | SR | Speech Recognition |
| 126. | SSMS | SQL Server Management Studio |
| 127. | SVD | Single Value Decomposition |
| 128. | TCP/IP | Transmission Control Protocol/Internet Protocol |
| 129. | TF-IDF | Term Frequency-Inverse Document Frequency |
| 130. | TPU | TensorFlow Processing Unit |
| 131. | TSDM | Time Series Data Mining |
| 132. | UI | User Interface |
| 133. | UTF-8 | Unicode Transformation Format-8 |
| 134. | VADER | Valence Aware Dictionary and sEntiment Reasoner |
| 135. | VBS | Visual Basic Script |
| 136. | VLSI | Very-Large-Scale Integration |
| 137. | VM | Virtual Machine / Virtual Memory |
| 138. | VSAM | Video Surveillance and Monitoring |
| 139. | VSM | Vector Space Model |
| 140. | W3C | World Wide Web Consortium |
| 141. | XAML | Extensible Application Markup Language |
| 142. | XGBoost | eXtreme Gradient Boosting |
| 143. | XML | eXtensible Markup Language |



